
Linux APUE学习:6、C程序的多进程
Linux APUE学习:6、C程序的多进程
本章介绍 UNIX 系统的进程控制,包括创建新进程、执行程序和进程终止。还将说明进程属性的各种 ID一一实际、有效和保的用户 和 D,以及它们如受到进控制的影本章还包括了解释器文件和 system函数。
代码参考
https://github.com/RoxyKko/APUE/tree/master/ch4
进程标识
每个进程都有一个非负整型表示的唯一进程ID。因为进程ID标识符总是唯一的,常将其用作其他标识符的一部分以保证其唯一性。例如,应用程序有时就把进程ID作为名字的一部分来创建一个唯一的文件名。
每个进程标识符在进程运行时总是唯一的,但进程标识符也可复用的。当一个进程终止后,其进程ID就成为复用的候选者。大多数UNIX系统实现延迟复用算法,使得赋予新建进程的ID不同于最近终止进程所使用的进程ID。这一操作可以避免将新进程误认为是使用同一进程ID号的已经终止的某个进程。
系统中有一些专用进程,但具体细节随着进程功能所实现不同。
- ID为0的进程通常为
调度进程,也称为交换进程(swapper)。此进程是内核的一部分,它并不会调用任何磁盘上的程序,因此也被成为系统进程 - ID为1的进程通常是
init进程,在自举过程结束时由内核调用。该进程的程序文件在UNIX早期版本中是/etc/init,在较新版本中为/sbin/init。此进程负责在自举内核后启动一个UNIX系统。init进程通常读取与系统有关的初始化文件(/etc/rc*文件或/etc/inittab文件,以及在/etc/init.d中的文件),并将系统引导到一个状态(如多用户)init进程决不会中止- 它是一个以超级用户特权运行的普通的用户进程
init进程是所有孤儿进程的父进程
- ID为2是页守护进程(page daemon),此进程负责支持虚拟存储器系统的分页操作。
init进程是Linux 系统的初始化进程,该进程会创建其他子进程来启动不同写系统服务,而每个服务又可能创建不同的子进程来执行不同的 程序。所以init进程是所有其他进程的“祖先”,并且它是由Linux内核创建并以root的权限运行,并不能被杀死。
Linux 中维护着一个数据结构叫做进程表,保存当前加载在内存中的所有进程的有关信息,其中包括进程的 PID(Process ID)、进程的状态、 命令字符串等,操作系统通过进程的 PID 对它们进行管理,这些 PID 是进程表的索引。
1 | // 下列函数从进程表中获取进程的有关信息 |
注:这些函数都没有出错返回
fork()系统调用
Linux下有两个基本的系统调用可以用于创建子进程:fork()和vfork()。fork在英文中是”分叉”的意思。为什么取这个名字呢? 因为一个进程在运行中,如果使用了fork,就产生了另一个进程,于是进程就”分叉”了,所以这个名字取得很形象。
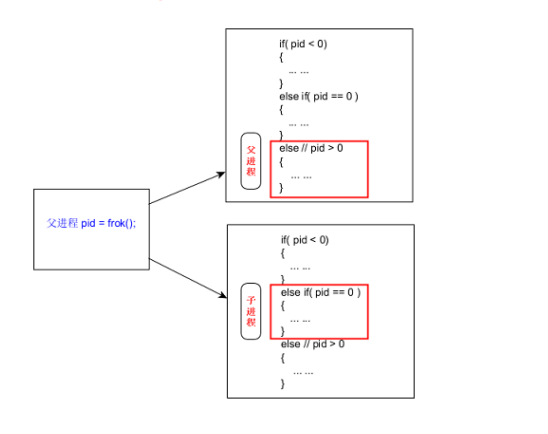
在我们编程的过程中,一个函数调用只有一次返回(return),但由于fork()系统调用会创建一个新的进程,这时它会有两次返回。一次返回 是给父进程,其返回值是子进程的PID(Process ID),第二次返回是给子进程,其返回值为0。所以我们在调用fork()后,需要通 过其返回值来判断当前的代码是在父进程还是子进程运行,如果返回值是0说明现在是子进程在运行,如果返回值>0说明是父进 程在运行,而如果返回值<0的话,说明fork()系统调用出错。
将子进程PID返回给父进程的原因是:
一个进程的子进程可以有多个,并且没有一个函数使一个进程可以获得其所有子进程的进程PID。
fork()使子进程得到返回值0的原因是: 一个进程只会有一个父进程,所以子进程总是可以调用
getpid()以获取其父进程的PID(进程PID==0的进程总是由内核交换进程使用,所以一个子进程的进程PID不可能为0)
fork 函数调用失败的原因主要有两个:
- 系统中已经有太多的进程;
- 该实际用户 ID 的进程总数超过了系统限制。
fork()函数的简单使用
子进程和父进程继续执行 fork 调用之后的指令。子进程是父进程的副本。例如,子进程获得父进程数据空间、堆和栈的副本。注意,这是子进程所拥有的副本。父进程和子进程并不共享这些存储空间部分。父进程和子进程共享正文段
系统在创建新的子进程成功后,会将父进程的文本段、数据段、堆栈都复制一份给子进程,但子进程有自己独立的空间,子进程对这些内存的修改并不会影响父进程空间的相应内存。这时系统中出现两个基本完全相同的进程(父、子进程),这两个进程执行没有固定的先后顺序,哪个进程先执行要看系统的进程调度策略。如果需要确保让父进程或子进程先执行,则需要程序员在代码中通过进程间通信的机制来自己实现。
1 |
|
运行结果:

在编程时,任何位置的
exit()函数调用都会导致本进程(程序)退出,main()函数中的return()调用也会导致进程退出,而 其他任何函数中的return()都只是这个函数返回而不会导致进程退出。
fork()函数的进阶部分
1 |
|
运行结果:
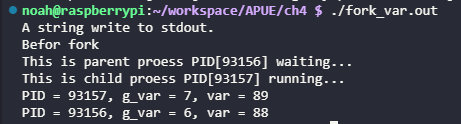
在上面的编译运行过程我们可以看到,父进程在代码第21行创建了子进程后,系统会将父进程的文本段、数据段、堆栈都拷贝 一份给子进程,这样子进程也就继承了父进程数据段中的的全局变量g_var和局部变量var的值。
- 因为进程创建之后究竟是父进程还是子进程先运行没有规定,所以父进程在第35行调用了sleep(1)的目的是希望让子进程先运行,但这个机制是不能100%确定能让子进程先执行,如果系统负载较大时1秒的时间内操作系统可能还没调度到子进程运行,所以sleep()这个机制并不可靠,这时候我们需要使用到今后学习的进程间通信机制来实现这种父子进程之间的同步问题;
- 程序中44行的
printf()被执行了两次,这是因为fork()之后,子进程会复制父进程的代码段,这样44行的代码也被复制给子进程了。而子进程在运行到第44行后并没有调用return()或exit()函数让进程退出,所以程序会继续执行到44行至45行调用return 0退出子进程;同理父进程也是执行44行至45行才让父进程退出,所以44行的printf()分别被父子进程执行了两次。 - 子进程在第33行和34行改变了这两个变量的值,这个改变只影响子进程的空间的值,并不会影响父进程的内存空间,所以子进程里g_var和var分别变成了7和89,而父进程的g_var和var都没改变
若将stdout重定向输出至tmp.log
1 | ./fork.out > tmp.log |
结果:
1 | A string write to stdout. |
第二次运行时,我们将标注输出重定向到了tmp.log文件中,这时我们发现13行处的”A string write to stdout.”在两次执行的 过程中都只打印了一次,而19行处的”Befor fork” 却在重定向执行时打印了两次。这是因为:
- write()系统调用是不带缓冲的,不管是否有重定向,13行的输出会立刻输出到标准输出里;
printf()库函数在标准输出是终端时默认是行缓冲,而当标准输出重定向到文件中后该函数是全缓冲的;这样19行printf()在第一次没有重定向执行时碰到换行符(\n)时就立刻输出到标准输出里了,而第二次因为有重定向,这时的打印内容并不会输出到标准输出而是存放在缓冲区中。在第21行调用**fork()创建子进程时,系统会将缓冲区的内容也复制给了子进程,这样父子进程的printf()缓冲区里都有”Befor fork”的内容。父子进程在运行至38行的时候printf()缓冲区里的内容 还没有达到缓冲区的大小,而并不会打印,直到父子进程都执行到39行调用return 0时才会导致进程退出。而进程在退出 的时候会自动Flush缓冲区里的数据,这时候才会将缓冲区的内容输出到标准输出tmp.log文件中。所以这种情况下”Befor fork”会被打印两次。**
子进程所继承父进程的哪些东西
从上面的例子中我们可以知道,知道子进程从父进程那里继承什么或未继承什么将有助于我们今后的编程。下面这个名单会因 为 不同Unix的实现而发生变化,所以或许准确性有了水份。请注意子进程得到的是 这些东西的 拷贝,不是它们本身。
由子进程从父进程继承:
- 进程的资格:真实(real)/有效(effective)/已保存(saved)、用户号(UIDs)和组号(GIDs)
- 环境变量(environment)
- 堆栈
- 内存
- 打开文件的描述符(注意对应的文件的位置由父子进程共享, 这会引起含糊情况)
- 执行时关闭(close-on-exec) 标志 (close-on-exec标志可通过
fnctl()对文件描述符设置,POSIX.1要求所有目录 流都必须在exec函数调用时关闭。更详细说明, 参见《APUE》 W. R. Stevens, 1993, 尤晋元等译 3.13节和8.9节) - 信号(signal)控制设定
- nice值(nice值由nice函数设定,该值表示进程的优先级,数值越小,优先级越高)
- 进程调度类别(scheduler class) (进程调度类别指进程在系统中被调度时所属的类别,不同类别有不同优先级,根据进程调度类别和nice值,进程调度程序可计算出每个进程的全局优先级(Global process prority),优先级高的进程优先执行)
- 进程组号
- 对话期ID(Session ID) (译文取自《高级编程》,指:进程所属的对话期 (session)ID, 一个对话期包括一个或多 个进程组, 更详细说明参见《APUE》 9.5节)
- 当前工作目录
- 根目录 (根目录不一定是“/”,它可由chroot函数改变)
- 文件方式创建屏蔽字(file mode creation mask (umask))
- 资源限制
- 控制终端
子进程所独有:
- 进程号
- 不同的父进程号(译者注: 即子进程的父进程号与父进程的父进程号不同, 父进程号可由getppid函数得到)
- 自己的文件描述符和目录流的拷贝(目录流由opendir函数创建,因其为顺序读取,顾称“目录流”)
- 子进程不继承父进程的进程,正文(text), 数据和其它锁定内存(memory locks) (锁定内存指被锁定的虚拟内存 页,锁定后, 不允许内核将其在必要时换出(page out), 详细说明参见《The GNU C Library Reference Manual》 2.2 版, 1999, 3.4.2节)
- 在tms结构中的系统时间(译者注:tms结构可由times函数获得, 它保存四个数据用于记录进程使用中央处理器 (CPU: Central Processing Unit)的时间,包括:用户时间,系统时间, 用户各子进程合计时间,系统各子进程合计时间)
- 资源使用(resource utilizations)设定为0
- 阻塞信号集初始化为空集
- 不继承由timer_create函数创建的计时器
- 不继承异步输入和输出
- 父进程设置的锁(因为如果是排他锁,被继承的话就矛盾了)










